





Sankey DiagramをRelationで作る
- Yoshitaka Arakawa
- 2021年5月26日
- 読了時間: 5分
Sankey Diagramでブログ何本書くんだという感じですが...
Tableau 2020.2の新機能であるRelationを使用すると、おそらく一番簡単かつ実用的にSankey Diagramを実装できることに気付きましたので、ここにご紹介いたします。どれくらい簡単かと言うと、過去の記事を全て無かったことにして良いと思うほどに。
今回使用したWorkbookはこちらから。
また今回のアプローチではSankey Diagram描写用のダミーデータを使用します。
こちらからダウンロードをお願いします。
それでは見ていきましょう。
はじめに:Sankey Diagramを作る古典的な方法
今回のアプローチは、実は古典的な作り方とほとんど同じことをします。
Sankey Diagramの実用的な作り方は、自分の知る限り以下のブログが一番古いのかなと思います。
この記事の内容を元にして多少の改善が加わった手法が、以下のInformation Labのブログが出るまでは一般的だったように思います。
(同じ内容を解説した自分の記事もぜひ:Sankey Diagramをデータ加工なしで作ろう)
こちらのブログは「一切のデータ前処理なく」Sankey Diagramが作成できることから注目されました。
つまりそれまでの手法では(これから見ていくのですが)少し厄介なデータ加工を行わなければSankey Diagramは作れませんでした。
まずはその厄介さも含め、古典的な作り方を見ていきましょう。
まず初めに、使用するデータ(今回はSample Super Store)とModel.csv(ダミーデータ)をCROSS JOINさせます。

この結果、各レコードがダミーデータの行数だけ重複します。
SuperStoreデータでRow ID=1のデータを例示します。

古典的方法の一番の問題点は、このレコードの重複です。
今回のModel.csvは約100行ありますが、これはSankey Diagramの作成の為だけにデータを約100倍にすることを意味します。
元々100万行程度のデータなら、約1億行にまで増加しますね。
一方でこの方法を取る理由としては、Sankey Diagram描画のためのデータ点を明示的に作成することができます。
このあたりは後ほど見ていくとして、まずは必要な計算式を列挙します。
Dim 1
[Region]
Dim 2
[Category]
Chosen Measure
SUM([Sales])
Curve Function
1/(1+EXP(1)^-[T])
Sankey Arm Size
[Chosen Measure] / TOTAL([Chosen Measure])
今回の例ではRegion, Categoryごとに、売上構成比を見る場合を想定します。
Sankey Arm Sizeが売上構成比に相当します。
Curve Functionは各Tに対応した、地域0~1での曲線を描くために使用します。
今回はSigmoid曲線を使用しますが、これは正直範囲0~1であればなんでも良いです。

さて、Sankey DiagramではPolygonマークを使います。
つまり以下のように、Polygonの上側と下側を描画させるためのデータ点が必要になります。

このデータ点を作成していくための計算式を見ていきましょう。
Position 1 MAX
RUNNING_SUM([Sankey Arm Size])
Position 1 MIN
[Position 1 MAX] - [Sankey Arm Size]
Position 2 MAX
RUNNING_SUM([Sankey Arm Size])
Position 2 MIN
[Position 2 MAX] - [Sankey Arm Size]
Curve 1-2 MAX
[Position 1 MAX] + ([Position 2 MAX] - [Position 1 MAX]) * MIN([Curve Function])
Curve 1-2 MIN
[Position 1 MIN] + ([Position 2 MIN] - [Position 1 MIN]) * MIN([Curve Function])
Curve Polygon 1-2
CASE MIN([Min/Max])
WHEN 'Min' THEN [Curve 1-2 MIN]
ELSE [Curve 1-2 MAX]
END
計算式はシンプルなので説明は割愛しますが、気になる方は以下の記事が参考になると思います。そちらを参照ください。
そして以下のように各要素を配置すれば完成です。
Polygonを使うこと、PathをPathマークに入れることに注意してください。







この古典的な方法はCROSS JOINにより元データのデータ量が増加することを除けば、作成する計算式と設定が必要な表計算の数が少なく済むので、かなり実装がしやすい手法でした。
それでも現在あまり使われていないように思うのは、やはりこのCROSS JOINによる重複が厄介だからかなと。元データを100倍近く増やすのは困るので。
(もちろん事前にSankey用にデータを集計し、集計データに対してCROSS JOINという手もありますが…Sankey用にしか使えないデータソースを作るのは実践的ではありませんよね)
その意味でデータを増加させない手法、もう少し扱いやすくした手法を色々と自分含めたTableauコミュニティは考えてきたわけですが、今回はTableau 2020.2の新機能「Relation」を使用して、元データ自体のデータ増加を割けつつも、古典的な(使いやすい)形でのSankey Diagram実装を目指します。
Relationを使用してSankey Diagramを作る
2020.2の新機能(というより新データモデル)であるRelationについて、日本語では以下の記事が詳しいです。
今回使用する要点だけ述べると、リレーションで接続されたテーブルは、そのテーブルの項目が呼び出されない限りは結合されません。
例えば以下の図だと、ビュー上の項目は全てSuperStoreのOrdersから持ってきていますが、JOIN使用(左)では結合後の結果が出るのに対し、Relation使用(右)ではModel.csvの項目が使われていないので、データの結合が起きていないことが分かります。

そしてこの機能をSankey Diagramにどう応用するか。
結論から言えば、データソースをRelationを使用した以下の形に置き換えます。
これだけです。
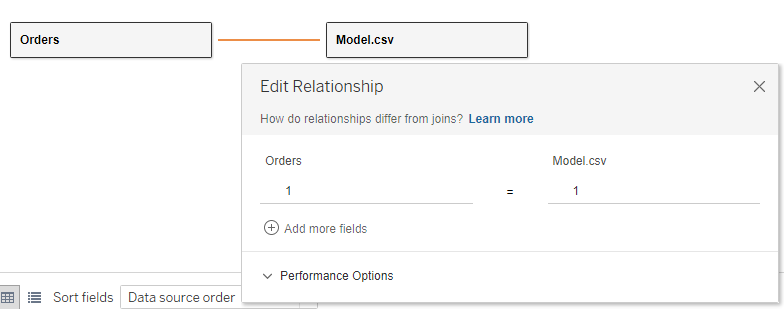
それ以外は全く変えることなく、同じSankey Diagramを作成できます。

一方で先述の通り、Model.csvの項目を使用しない限りはSuperStoreのデータそのままとして使用できるので「Sankey Diagram専用のデータソース」を作成するというよりは「Sankey Diagramも作成できるデータソース」を作ることができます。
つまり以下のようなダッシュボードを数値の重複を気にせずに作成できます。
(こちらは実際Workbookを見ていただければ分かるのですが、面倒な重複処理など一切していません)

元々の手法の問題点は「元データ自体をCROSS JOINで重複させる」ことでした。Relationを使えばSankey Diagramを作る場合にのみ重複を発生させるので、Data Densification使用したアプローチが目指していた「元データを重複させない」目的もある意味で達成できます。
その一方で計算式はかなり少なくなるので、実践的にSankey Diagramを作るのであれば、この手法が総合的に良いのではと思います。
最後に
何度かSankey Diagramの記事を書いてきましたが、この手法が一番楽だと思います。
一方でRelationが使えないケースでは、Data Densificationによる実装が選択肢にはなりますが…多分レアケースかなと。
前述のように、Sankey用のダミーデータをデータソースに足したとしても、参照されない限りは悪さをしないので、足せるなら足しても良いのかなと思います。
これからSankey Diagramを使う場合は、自分はこの方法で実装すると思います。
ぜひ試してみてください。
質問などありましたらTwitterかLinkedinでお願いします。それでは。